How many times have you designed a system as System Architect only to find at the end of the project - or at least soon after it went live - that one of the key interfaces into your system has been changed? Did your design cater for this scenario? How much time and resources did it take to implement the new interface? This article explains the use of isolation layers to isolate your system from any outside changes. It is highly effective, widely applicable but it can have a performance impact if not done properly.
The basic principle applies to systems that can be generalised to the following architecture:
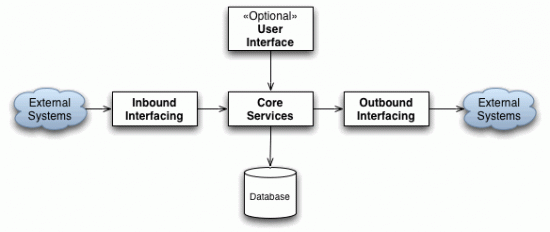
The system has some set of core services which implements the business logic, an optional user interface (typically present in systems such as these), a database with which the core services interact and inbound and/or outbound interfaces for importing and exporting information to/from the system. These interfaces are always B2B oriented. The potential problem with systems such as these is that keeping the dynamic nature of businesses in mind, it is inevitable that those interfaces will change sooner or later.
Typically the inbound interface will interpret the (potentially proprietary) data received, process it and then store it in the database. The reverse applies to the outbound interfaces - data will be read from the database, processed and (potentially converted to a proprietary format first) submitted to an external system. If you are in the fortunate position of being able to mandate the format used for interfacing to your system, and the format for the oubound interfaces; then this article does not really apply to you since you have control over the interfaces. The problem comes in when you do not mandate these interfaces (at least not all of them). Therefore you have no (or at least very little) control over the formats of the interfaces. Most of the times the outbound interface would not be under your control, unless your system is a completely new concept designed to be used as a core service by systems still to be created.
Many times a variety of inbound interfaces needs to be implemented in order to support a variety of existing systems. Whatever the case might be, you need to future proof your system otherwise a lot of work will be required everytime an interface is changed. Consider the following example of a system as it is typically implemented:
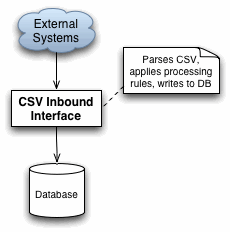
Suppose an existing client has a predefined format that they need to submit to your system for processing. The data arrives in a flat file in Comma Separated Value format. Your inbound interface polls a spool directory, and the moment the file arrives it picks it up, parses it, applies some business logic processing to the data then writes it away to the database. Now consider one of two scenario's. What will you do should
- Another client need to use your system but they are using an XML format?
- The existing client decide to change their outbound format?
When using the design shown above, for the first scenario you'll most likely have to write another interface identical to the first, but that parses XML instead of CSV. The business logic is now duplicated - a breeding nest for bugs and high maintenance costs. For the second scenario, the interface code most probably needs to change. This implies someone needs to work with a module that contains both the CSV parsing code, as well as the business logic and DB code. This might be a potentially large module, and it would be easy for someone to break something since there is no isolation between the business logic, the DB and the CSV parsing code.
Consider the following example, where the previous example was modified to provide a system using isolation layers:
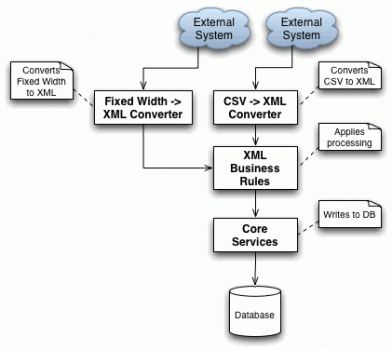
The principle underlying this example is the use of an isolation layer, namely the intermediate XML conversion step. The idea is to define a standard XML format (or whatever format suits your system) which contains the common subset of data of all the proprietary interfaces. A small converter parses the proprietary CSV format of the client and creates the standard XML format, which is fed into the next module. The next module applies the business logic to that XML format, and submits the results to the Core Services for DB storage. The key thing to understand is that by introducing the XML layer, we have gained the following advantages:
- Separated business logic from proprietary CSV file parsing and DB updates
- Allows the business logic to be written once and applied to all potential proprietary format converters
- Allows for the easy addition of trivial proprietary converters with no changes required to the business logic or DB updating code.
Unfortunately there is a small price to pay for this - the extra step can be bad for the performance of the system since the conversion has to occur twice - once for CSV -> XML, and once for XML -> DB. This is especially bad when using XML as the isolation layer format, since XML is known to be bulky and slow. However, by paying special attention to the coding of the interface, it would be possible to optimise most of these bottlenecks away, such as making use of the SAX parser instead of the DOM parser.