Writing secure code is normally only taught in advanced, highly specialized courses. This is very unfortunate as it is because of this single reason that phenomena like worms, viruses and crackers can cause the damage they do.
Solving this deficiency in knowledge and skills is both highly complex and surprisingly simple. The reason is well known - it is called the Pareto principle. Simply stated, it postulates that for 20% effort put in to something you will reap 80% of the benefits. In our scenario, this postulates that with 20% effort you will be able to reduce the risk of writing insecure software by 80%. This is in truth not far off...
Most gross insecurities are a direct result of easily solved software deficiencies, or better known as software bugs. This article covers many important aspects regarding both obvious security flaws, as well as subtle issues. It is not a thorough coverage of the topic as one can write entire books on the subject. The intention is to make the reader aware of the more common 20% security risks, and touch base on some of the other 80%.
I have written a piece of code below that is typically used in web portals. This code is vulnerable to a well known security issue. See if you can find it...
class Auth {
public boolean authenticateUser(String pUserName, String pPassword) {
String vSQL = "select user_id from user where username = '"+pUserName+
"' AND password = '"+pPassword+"'";
int vUserID = performSQLQuery(vSQL); // executes the actual SQL query
if (vUserID > 0)
return true;
else
return false;
}
}
Could you spot the problem if this code were to be called by a system that acquires the user name and password
values directly from the user? Consider what would happen if the user typed in Piet for the pUserName
parameter and 12345 for the pPassword parameter. The SQL query would evaluate to:
select user_id from user where username = 'Piet' AND password = '12345'
There is nothing wrong with that SQL query. The problem comes in when the user types in say 1' OR 1==1;
-- for the pUserName parameter and anything else for the pPassword parameter.
See what happens:
select user_id from user where username = '1' OR 1==1; --' AND password = 'ANYTHING'
which is equal to
select user_id from user where username = '1' OR 1==1;
If you understand SQL well, you will realise that that SQL query is completely different to that which I
originally intended! In this specific scenario, the user has changed the SQL query to retrieve all rows where username
is equals to 1, OR where 1 == 1. Because the last condition will always
evaluate to true, the complete condition will always evaluate to true. And because the two
-- characters were inserted, the modified SQL statement will ignore all the rest of the characters as
they are now commented out. This helps the user construct a valid SQL statement by means of parameter contamination,
or better known as SQL injection.
Hopefully you are shocked by this if you have not seen it before. The bottom line is that that innocent code
(which is used widely throughout the world in many real systems) allows the user - without any special
permissions or privileges - to execute arbitrary SQL statements by just typing a specially crafted SQL fragment
into one of the input fields, right from the user interface. In this scenario, the user will have been granted
access to the system without even knowing the correct username, nevertheless the correct password! Consider one
more example, just to scare you to death. Say the user typed in for pUserName the value 1';
delete from user; --. The SQL query would evaluate to:
select user_id from user where username = '1'; delete from user; --'
AND password = 'ANYTHING'
which is equal to
select user_id from user where username = '1';
delete from user;
In this situation the user was not interested in being granted access to the system, rather he was interested in
destroying the data in the user table. The first SELECT query would fail. However, a second SQL
query was specified with the ; operator, which will then be executed and deleting all the users in
the user table. Usually web servers connect to back end databases with one RDBMS userid, which has full access
to the corresponding tables. Hence this will be destructive in most scenario's.
Fortunately for us this is one of those 20% situations in which it is rather easy to provide a patch for this code. The root of the problem is unchecked user input, which can be remedied with code as follows.
class Auth {
public boolean authenticateUser(String pUserName, String pPassword) {
String vSQL = "select user_id from user where username = ? AND password = ?;
int vUserID = performSQLQuery(bindParameters(vSQL,pUserName,pPassword));
if (vUserID > 0)
return true;
else
return false;
}
private String bindParameters(String pSQL, String pUserName,String pPassword) {
// Replacing the ? with the parameter can be done in many other ways.
// This is ad-hoc code and not tested!
return vSQL.replaceFirst("\?",
escape(pUserName)).replaceFirst("\?",escape(pPassword));
}
private String escape(String pString) {
StringBuffer vRes = new StringBuffer();
for (int i=0;i<pString.length;i++) {
if (pString.charAt(i) == '\'')
vRes.append("'");
vRes.append(pString.charAt(i));
}
return "\"" + vRes.toString() + "\"";
}
}
This is not the most elegant solution, and will break for many reasons (such as the pUserName
containing the ? character etc.) The code does show a fix however, and that is to make sure you
escape the ' character with another one. Depending on the RDBMS flavour you are running, it might
be necessary to escape other characters as well. This code will not be exploitable using the standard
' SQL Injection technique.
If you are very clever you would notice that the aforementioned "fix" is not really a fix at all. By plugging one hole we have allowed another vulnerability to creep in. What would that "fix" do with the following user input.
select user_id from user where username = '1\'; delete from user; --'
AND password = 'ANYTHING'
This would translate to
select user_id from user where username = '1\'';
delete from user;
Can you see that the escaping does not work in the example? When the user used another means of escaping the
quote character by specifying \', it effectively rendered the extra quote we inserted useless as it
is seen as part of the parameter. Therefore our escaping caused this vulnerability (which did not previously
exist) to become exploitable. How do we fix this? I think at this stage it should be obvious that we will have
to apply heuristics in order to achive a set level of confidence. This is because of vendor extensions and
dialects. By using these techniques one will never have full confidence that it is secure. The only reliable,
generic way around this is to use another method of passing parameters to the database. One such method is to
make use of PreparedStatement's, as the RDBMS server will perform the parameter binding to the
? placeholder.
If this section caused you to realize that one cannot have confidence in a security fix just because it fixes the specific security exploit - it was worth my while writing it. Always test your code for all known vulnerabilities, and also use common sense in assessing the strength of a security fix.
Most people have heard about Buffer Overflows. This is a condition where data overrun the space allocated for it in memory. Without going into too much technical details, in essence the following code will be vulnerable to a buffer overflow.
int main(int argc, char* argv[]) {
char* vBuffer = new char[10];
char vDelete;
printf("Type Y to delete ALL YOUR EMAIL, N otherwise: ");
vDelete = getchar();
printf("Type in your name: ");
vBuffer = gets(vBuffer);
if (vDelete == 'Y') {
deleteEverything();
printf("Deleted %s's data\n",vBuffer);
}
else
printf("NOT deleted %s's data\n",vBuffer);
}
What happens if the user types in a name that is equal or longer to 10 characters? In C/C++, a string is always
null terminated. That means the total length of the string as read in by the user, will be that length + 1 (for
the \0 character). Assuming the user typed in a long string, the following will happen in memory.
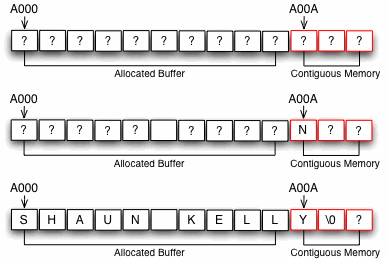
Assume that the variable vBuffer is stored at memory location A000, as indicated in the
diagram. As you can see there are 10 bytes allocated to the variable. Assume further that the memory location
A00A points to the variable vDelete, which is a single byte in length. Lets assume the
user's name is Shaun Kelly and that he does not want to delete all his email.
Therefore the program's output will look like this:
>Type Y to delete ALL YOUR EMAIL, N otherwise: N
>Type in your name: SHAUN KELLY
>Deleted SHAUN KELLY's data
The obvious question is: Why did the system delete his data if he said N for No? The answer is
simple - the user's name was too long for the buffer allocated for it, and overflowed into the adjacent memory
cells, in this case they happened to belong to vDelete. Starting from the beginning, the memory
area is filled with random data (indicated by ?). In the second diagram, the user has specified
that he does not want to delete all his mail by typing in a N, and this is stored
in memory location A00A. In the third diagram, he typed in his full name. However, only the first
10 characters of his name fits in to the buffer allocated to vBuffer. The 11th character
Y overflowed into memory location A00A - the start of the vDelete
variable's memory location. This Y then overwrote the N that was previously stored
there. If the code now tries to determine whether to delete all the mail, it would retrieve an incorrect value
of Y for the vDelete variable.
There is a simple way to solve this issue - and that is to increase the buffer's capacity. Unfortunately this
will only delay the inevitable buffer overrun for the time when a really long name is typed in. Therefore the
secure way to resolve this is to use a secure API method, as the whole issue is caused by gets()
not checking the buffer's boundaries. The code can be written securely as follows.
int main(int argc, char* argv[]) {
char* vBuffer = new char[15];
char vDelete;
printf("Type Y to delete ALL YOUR EMAIL, N otherwise: ");
vDelete = getchar();
printf("Type in your name: ");
vBuffer = fgets(vBuffer,sizeof(vBuffer)-1,stdin);
if (vDelete == 'Y') {
deleteEverything();
printf("Deleted %s's data\n",vBuffer);
}
else
printf("NOT deleted %s's data\n",vBuffer);
}
It is important to note that the memory locations of the declared variables are never guaranteed to be
consecutive, or for that matter at any specific location in memory. This is especially true for variables that have
been allocated memory from the global heap with the new operator or malloc()/calloc()
methods. Therefore the behaviour of buffer overflows are highly unpredictable.
A more dangerous exploit of buffer overflows is when the IP CPU register is manipulated to point to so-called shellcode, which will then get executed. The idea is simple. Once you found a buffer overflow condition (in Unix, if the application segmentation fault's it is a candidate for a buffer overflow condition), try to manipulate the IP register by changing entries in the stack so that it returns to your shellcode. Once this has been accomplished, code of your choice can be executed with the privilege of the user the process is running under. Shellcode is assembly code carefully crafted and attached to the payload intended for the vulnerable buffer. In our case, should we have wanted to exploit the buffer overflow using shellcode, we would have appended our shellcode to the end of the long string. This is a complex process and the offsets need to be perfectly aligned with the IP register's contents. This can once again be avoided by avoiding the buffer overflow condition in the first place. Malicious code cannot get executed this way if it never makes it into memory...
Framework development is something most developers avoid as it is complex and best left to experts. Without going into too much detail, I want to touch base on the issue of enabling security options in a framework.
(Security conscious) Designers always have to balance the equation between usability on the one hand and security
on the other. A good example is what happened to me with the development of the WebMVC framework. It has a
BinaryJSPView class that allows you to specify a file to send to the client browser. This method
takes the name of the file and the file's contents as model attributes, and will then submit this data to the
client.
Assume your web frontend code passes the name of a file to download as a GET/POST HTTP request, and the
corresponding handler retrieves the file and forwards the request to the BinaryJSPView object. I
realised immediately that this is a very vulnerable situation as the following scenario shows. Assume the file
to be downloaded is located at /opt/jakarta-tomcat/webapps/myapp/downloads/file.zip. Assume the web
frontend specifies the file file.zip to be downloaded. It is extremely easy for a web user to
change this so that the file to be downloaded points to say ../../../../../etc/passwd. Appended to
the original path this gives /opt/jakarta-tomcat/webapps/myapp/downloads/../../../../../etc/passwd,
which is equivalent to /etc/passwd. Therefore the user has access to the contents of all files with
a known file name, and that the user the web server is running under has access to. Scary!
This is easily resolved by changing BinaryJSPView to check the filename given for any signs of the
../ substring. However, doing this disallows the legitimate use of that feature. Therefore we have
a classic tradeoff between security and usability. At first I was tempted at solving this by adding a parameter
called METHOD_PARANOID_FILE_PATH_CHECK to the BinaryJSPView class, and if set, perform
a rigorous and paranoid check on the filename. Therefore if there is a legitimate use of the ../
characters in the filename, this parameter should not be set. In all other situations this parameter should be
set for security reasons. With experience comes the great knowledge that people do not read manuals, therefore a
term such as RTFM had been coined :). In addition developers are lazy, therefore nobody would take the time to
read up on that added parameter and how to use it. That is why I have decided to make that parameter's default
value active, hence it can be overridden by turning it explicitly off. So the philosophy is
that lazy developers will have the secure option enabled by default, and only when running into troubles because
of too strict security policies hampering their application, they can go RTFM and relax the restrictions a bit.
This is very much like most (competent) firewall administrators think by specifying a DENY ALL policy and then
only specifying ALLOW rules on a case by case basis.
Secure programming is a huge topic and I have only touched on some aspects. There are also big differences in writing secure programs for different operating systems. I recommend that you include security tests in addition to the usual functionality tests once you have completed your application. Tools such as nessus are great aids in finding network exploitable insecurities.